머신러닝 모델은 크게 트레이닝 과정과 테스트 과정으로 나뉜다.
▷ 트레이닝 과정 - 대량의 데이터와 충분한 시간을 들여 모델의 최적 파라미터를 찾음
▷ 테스트 과정 - 트레이닝 과정에서 구한 최적의 파라미터로 구성한 모델을 트레이닝 과정에서 보지 못한 새로운 데이터에 적용하여 모델이 잘 학습됐는지 테스트하거나, 실제 문제를 풀기 위해 사용
Data의 종류 = <Training Data, Validation Data, Test Data>
Validation Data
: 트레이닝 과정 중간에 사용하는 테스트 데이터
☞ 필요한 이유?
트레이닝 과정에서 학습에 사용하지는 않지만 중간중간 테스트하는데 사용해서 학습하고 있는 모델이 Overfitting에 빠지지 않았는지 체크하기 위해서
Overfitting(과적합)?
: 트레이닝 데이터에 대한 에러는 작아지지만 검증용 데이터에 대한 에러는 커지는 현상
즉, 트레이닝 데이터에만! 초점이 맞춰서 학습이 된 경우이다. 따라서 학습한 데이터에 대해서는 오차가 감소하지만 실제 데이터에 대해서는 오차가 증가하게 된다.
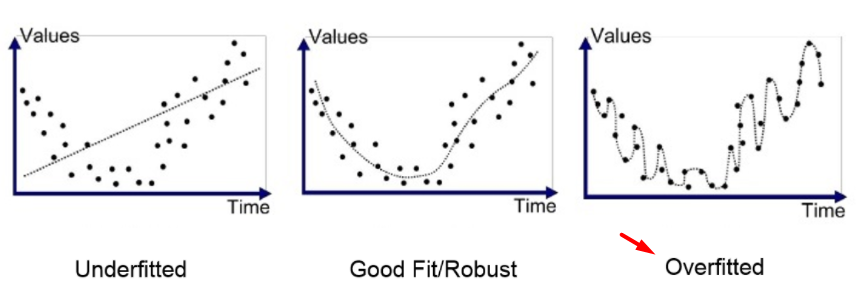
따라서 트레이닝 에러는 작아지지만 검증 에러는 커지는 지점에서 업데이트를 중지하면 최적의 파라미터를 얻을 수 있다.
'Study > Deep Learning' 카테고리의 다른 글
| TensorFlow (0) | 2021.10.15 |
|---|---|
| 다양한 Computer Vision 문제 영역 (0) | 2021.10.14 |
| 머신러닝 기본 프로세스 (0) | 2021.10.14 |
| 딥러닝의 응용분야 (0) | 2021.10.13 |
| 머신러닝/딥러닝 기초 (0) | 2021.10.13 |