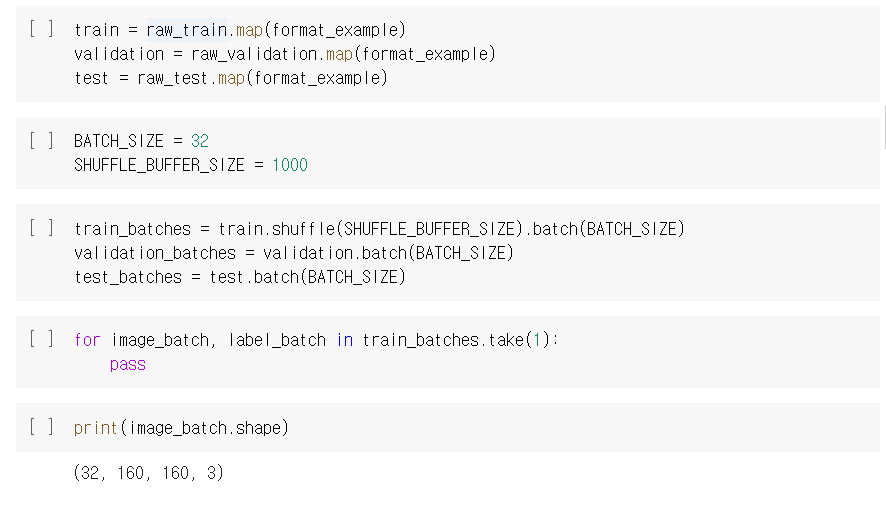
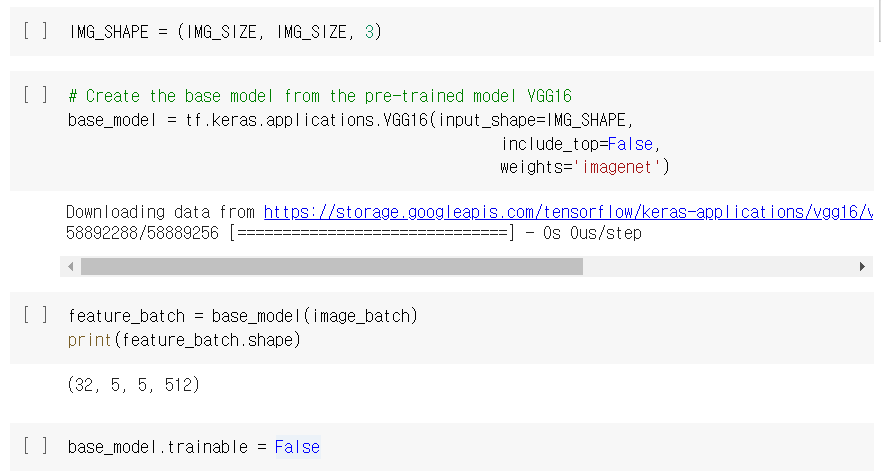
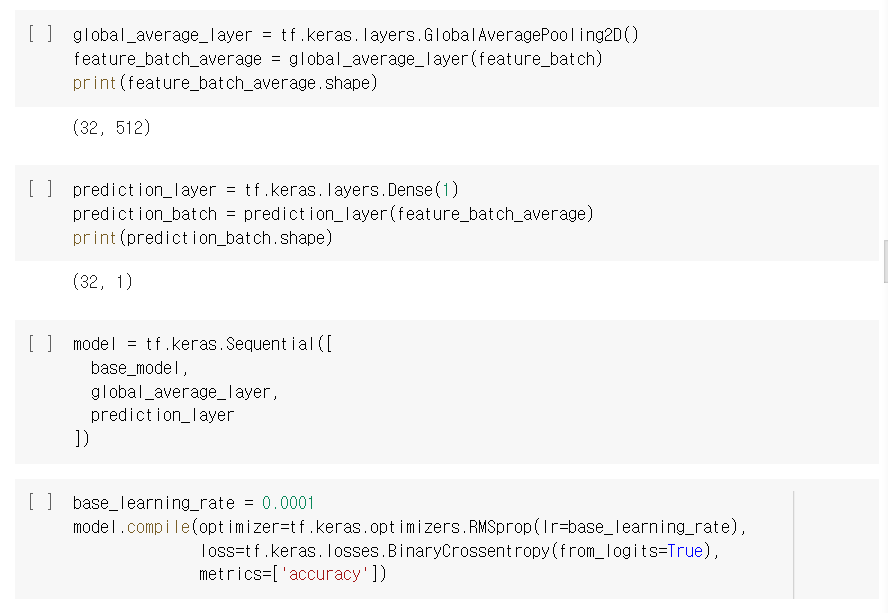
OpenCV
: 실시간 이미지/영상 처리에 사용하는 오픈 소스 라이브러리
: Python, C++, Java 와 같은 다양한 개발 환경을 지원
: Windows, Linux, Mac OS, iOS 및 Android같은 다양한 OS를 지원하는 크로스 플랫폼
Cascade Classifier : 다단계 분류
- Haar Cascade Object Detection 모듈
: 머신러닝 기반 Object Detection 알고리즘. OpenCV의 대표적인 API
: 다수의 객체 이미지와 객체가 아닌 이미지를 cascade 함수로 트레이닝 시켜 객체 검출
: 미리 정해진 방식으로 인식(xml 파일에 학습데이터 저장되어 있음)
↔ Machine Learning : data training 방식
: 빠른 Object Detection 가능, 간단, 가벼움
: 정확도가 낮아 예외 사항에 약함
import cv2
import numpy as np
from tkinter import *
from PIL import Image
from PIL import ImageTk
from tkinter import filedialog
#xml에 있는 얼굴인식 파일정보를 기반으로 detection
face_cascade_name = './opencv/data/haarcascades/haarcascade_frontalface_alt.xml'
eyes_cascade_name = './opencv/data/haarcascades/haarcascade_eye_tree_eyeglasses.xml'
file_name = 'soccer.jpg'
title_name = 'Haar cascade object detection'
frame_width = 500 #사이즈가 크면 인식하는게 더 많기도 함(Haar cascade의 경우)
def selectFile():
file_name=filedialog.askopenfilename(initialdir="./", title="Select file",filetypes = (("jpeg files","*.jpg"),("all files","*.*")))
print('File name: ', file_name)
read_image = cv2.imread(file_name)
(height, width) = read_image.shape[:2]
frameSize = int(sizeSpin.get())
ratio = frameSize / width
dimension = (frameSize, int(height * ratio))
read_image = cv2.resize(read_image, dimension, interpolation = cv2.INTER_AREA)
image = cv2.cvtColor(read_image, cv2.COLOR_BGR2RGB)
image = Image.fromarray(image)
imgtk = ImageTk.PhotoImage(image=image)
detectAndDisplay(read_image)
def detectAndDisplay(frame):
frame_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)#Gray scale로 바꿔줌
frame_gray = cv2.equalizeHist(frame_gray) #히스토그램 이용 -> 디지털 이미지
#-- Detect faces
faces = face_cascade.detectMultiScale(frame_gray) #MultiScale 특정 영역.. 얼굴정보
for(x,y,w,h) in faces:
center = (x+w//2, y+h//2) #사각형(얼굴) 중간
frame = cv2.rectangle(frame, (x,y), (x+w, y+h), (0,255,0), 4) #녹색 사각형(두께4)그리기
faceROI = frame_gray[y:y+h, x:x+w] #관심영역 = 금방 선택한 얼굴
#-- In each face, detect eyes
eyes = eyes_cascade.detectMultiScale(faceROI)
for (x2,y2,w2,h2) in eyes:
eye_center = (x + x2 + w2//2, y + y2 + h2//2)
radius = int(round((w2 + h2)*0.25)) #반지금 구하기 : 정사각형모양에 0.25곱해서(4분의 1)실수, 반올림
frame = cv2.circle(frame, eye_center, radius, (255,0,0),4)
#cv2.imshow("Capture - Face detection", frame)
#버튼을 눌러 새로운 화면 보여줌
image = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
image= Image.fromarray(image)
imgtk = ImageTk.PhotoImage(image = image)
detection.config(image=imgtk)
detection.image = imgtk
#main
main = Tk()
main.title(title_name)
main.geometry()
read_img = cv2.imread(file_name)
(height, width) = read_img.shape[:2]
ratio = frame_width / width
dimension = (frame_width, int(height * ratio))
read_img = cv2.resize(read_img, dimension, interpolation = cv2.INTER_AREA)
image = cv2.cvtColor(read_img, cv2.COLOR_BGR2RGB) #이걸 안하면 색이 좀 빛바랜 것처럼 나옴
image = Image.fromarray(image)
imgtk = ImageTk.PhotoImage(image = image) #Tk Pillow 위에 그리기 위한 과정
#cv2.imshow("Original Image", image)
face_cascade = cv2.CascadeClassifier()
eyes_cascade = cv2.CascadeClassifier()
#-- 1. Load the cascades
if not face_cascade.load(cv2.samples.findFile(face_cascade_name)):
print("--(!) Error Loading face cascade")
exit(0)
if not eyes_cascade.load(cv2.samples.findFile(eyes_cascade_name)):
print("--(!) Error Loading eyes cascade")
exit(0)
label = Label(main, text=title_name) #타이틀
label.config(font=("Courier", 18))
label.grid(row=0, column=0, columnspan=4)
sizeLabel = Label(main, text='Frame Width : ')
sizeLabel.grid(row=1, column=0)
sizeVal = IntVar(value = frame_width)
sizeSpin = Spinbox(main, textvariable = sizeVal, from_=0, to=2000, increment=100, justify=RIGHT) #부모 윈도우 안에,,,
sizeSpin.grid(row=1, column=1)
Button(main, text="File Select", height=2, command=lambda:selectFile()).grid(row=1,column=2, columnspan=2)
detection = Label(main, image=imgtk)
detection.grid(row=2, column=0, columnspan=4)
detectAndDisplay(read_img)


'Study > Deep Learning' 카테고리의 다른 글
| Gradient Clipping (0) | 2021.10.20 |
|---|---|
| TensorFlow 2.0을 이용한 Char-RNN 구현 (0) | 2021.10.20 |
| Embedding (0) | 2021.10.20 |
| 순환신경망(RNN) (0) | 2021.10.19 |
| Pre-Trained CNN 모델을 이용한 Image Classification (0) | 2021.10.18 |