더보기
# -*- coding: utf-8 -*-
from __future__ import absolute_import, division, print_function, unicode_literals
from absl import app
import tensorflow as tf
import numpy as np
import os
import time
# supervised learning을 위한 training data set 구성
# input 데이터와 input 데이터를 한글자씩 뒤로 민 target 데이터를 생성하는 utility 함수를 정의
def split_input_target(chunk):
input_text = chunk[:-1] #한글자 뒤로 밀기 전 text
target_text = chunk[1:] #한글자 뒤로 민 text
return input_text, target_text
# 학습에 필요한 설정값들을 지정
data_dir = tf.keras.utils.get_file('shakespeare.txt', 'https://storage.googleapis.com/download.tensorflow.org/data/shakespeare.txt') # 셰익스피어 희곡 다운로드
batch_size = 64 # Training : 64, Sampling : 1 , 한 번의 mini-batch gradient descent 실행할 때의 개수
seq_length = 100 # Training : 100, Sampling : 1 , 몇 글자를 하나의 시계열로 볼 것인지
embedding_dim = 256 # Embedding matrix에서 형변환 하는 차원수
hidden_size = 1024 # RNN 히든 레이어의 노드 개수
num_epochs = 10 # 전체 학습 반복 횟수
# 학습에 사용할 txt 파일을 읽음
text = open(data_dir, 'rb').read().decode(encoding='utf-8')
# 학습데이터에 포함된 모든 character들을 나타내는 변수인 vocab과 vocab에 id를 부여해 dict 형태로 만든 char2idx를 선언
vocab = sorted(set(text)) # 유니크한 character 개수. 단어집합 생성
vocab_size = len(vocab)
print('{} unique characters'.format(vocab_size))
char2idx = {u: i for i, u in enumerate(vocab)} # character와 인덱스(int)를 연결시켜 하나의 dictionary 형태로 만들어줌
idx2char = np.array(vocab)
# 이렇게 만든 dictionary를 이용해 모든 글자(character)를 integer 변환을 수행, numpy array로 만듬
text_as_int = np.array([char2idx[c] for c in text])
# split_input_target 함수를 이용해서 input 데이터와 input 데이터를 한글자씩 뒤로 민 target 데이터를 생성
# sequence 개수만큼 묶은 후, batch 사이즈로 묶음
char_dataset = tf.data.Dataset.from_tensor_slices(text_as_int)
sequences = char_dataset.batch(seq_length+1, drop_remainder=True) # sequence 수만큼 묶음
dataset = sequences.map(split_input_target)
# tf.data API를 이용해서 데이터를 섞고 batch 형태로 가져옴
dataset = dataset.shuffle(10000).batch(batch_size, drop_remainder=True) # 전체 데이터를 batch 단위로 묶음
# tf.keras.Model을 이용해서 RNN 모델을 정의
class RNN(tf.keras.Model):
def __init__(self, batch_size):
super(RNN, self).__init__()
self.embedding_layer = tf.keras.layers.Embedding(vocab_size, embedding_dim,
batch_input_shape=[batch_size, None])
self.hidden_layer_1 = tf.keras.layers.LSTM(hidden_size,
return_sequences=True,
stateful=True,
recurrent_initializer='glorot_uniform')
self.output_layer = tf.keras.layers.Dense(vocab_size)
def call(self, x):
embedded_input = self.embedding_layer(x)
features = self.hidden_layer_1(embedded_input)
logits = self.output_layer(features)
return logits
# sparse cross-entropy 손실 함수를 정의☆
def sparse_cross_entropy_loss(labels, logits):
return tf.reduce_mean(tf.keras.losses.sparse_categorical_crossentropy(labels, logits, from_logits=True))
# 최적화를 위한 Adam 옵티마이저를 정의
optimizer = tf.keras.optimizers.Adam()
# 최적화를 위한 function을 정의
@tf.function
def train_step(model, input, target):
with tf.GradientTape() as tape:
logits = model(input)
loss = sparse_cross_entropy_loss(target, logits)
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
return loss # 현재 상태의 loss function 값 반환
def generate_text(model, start_string):
num_sampling = 4000 # 생성할 글자(Character)의 개수를 지정
# start_string을 integer 형태로 변환
input_eval = [char2idx[s] for s in start_string] # 처음 input으로 들어온 character를 int로 변환
input_eval = tf.expand_dims(input_eval, 0)
# 4000개의 전체 샘플링 결과로 생성된 string을 저장할 배열을 초기화
text_generated = []
# 낮은 temperature 값은 더욱 정확한 텍스트를 생성
# 높은 temperature 값은 더욱 다양한 텍스트를 생성
temperature = 1.0
# 여기서 batch size = 1
model.reset_states()
for i in range(num_sampling):
predictions = model(input_eval)
# 불필요한 batch dimension을 삭제
predictions = tf.squeeze(predictions, 0)
# argmax 샘플링 시 결과의 다양성이 사라지기 때문에
# argmax의 장점은 가져가고 랜덤성은 높이는 것이 필요함
# 따라서 모델의 예측결과에 기반해서 랜덤 샘플링을 하기위해 categorical distribution을 사용
predictions = predictions / temperature
predicted_id = tf.random.categorical(predictions, num_samples=1)[-1,0].numpy()
# 예측된 character를 다음 input으로 사용
input_eval = tf.expand_dims([predicted_id], 0)
# 샘플링 결과를 text_generated 배열에 추가
text_generated.append(idx2char[predicted_id])
return (start_string + ''.join(text_generated))
def main(_):
# Recurrent Neural Networks(RNN) 모델을 선언
RNN_model = RNN(batch_size=batch_size)
# Sanity Check - 하나의 데이터를 뽑아 문제가 없는지 확인
# 데이터 구조 파악을 위해서 예제로 임의의 하나의 배치 데이터 예측하고, 예측결과를 출력
for input_example_batch, target_example_batch in dataset.take(1):
example_batch_predictions = RNN_model(input_example_batch)
print(example_batch_predictions.shape, "# (batch_size, sequence_length, vocab_size)")
# 현재 모델 구조를 출력
RNN_model.summary()
# checkpoint 데이터를 저장할 경로를 지정
checkpoint_dir = './training_checkpoints' # 학습 중간중간의 파라미터 저장
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt_{epoch}")
for epoch in range(num_epochs):
start = time.time()
# 매 반복마다 hidden state 초기화(최초의 hidden 값은 None)
hidden = RNN_model.reset_states()
for (batch_n, (input, target)) in enumerate(dataset): # 데이터 셋에 있는 것들을 batch 단위로 가져옴
loss = train_step(RNN_model, input, target)
if batch_n % 100 == 0: # 100번의 gradient descent 수행할 때마다
template = 'Epoch {} Batch {} Loss {}'
print(template.format(epoch+1, batch_n, loss)) # 현재 상태의 loss 값 출력
# 5회 반복마다 파라미터 결과값을 checkpoint로 저장
if (epoch + 1) % 5 == 0:
RNN_model.save_weights(checkpoint_prefix.format(epoch=epoch))
print ('Epoch {} Loss {:.4f}'.format(epoch+1, loss)) # 매 epoch 마다 loss 값 감소량 출력
print ('Time taken for 1 epoch {} sec\n'.format(time.time() - start))
RNN_model.save_weights(checkpoint_prefix.format(epoch=epoch))
print("트레이닝이 끝났습니다!")
# 실제 sampling을 위한 RNN 구조 생성
sampling_RNN_model = RNN(batch_size=1)
sampling_RNN_model.load_weights(tf.train.latest_checkpoint(checkpoint_dir)) # 학습해놨던 파라미터를 불러옴
sampling_RNN_model.build(tf.TensorShape([1, None]))
sampling_RNN_model.summary()
# 샘플링 시작
print("샘플링을 시작합니다!")
print(generate_text(sampling_RNN_model, start_string=u' ')) # 공백부터 시작
if __name__ == '__main__':
# main 함수 호출
app.run(main)

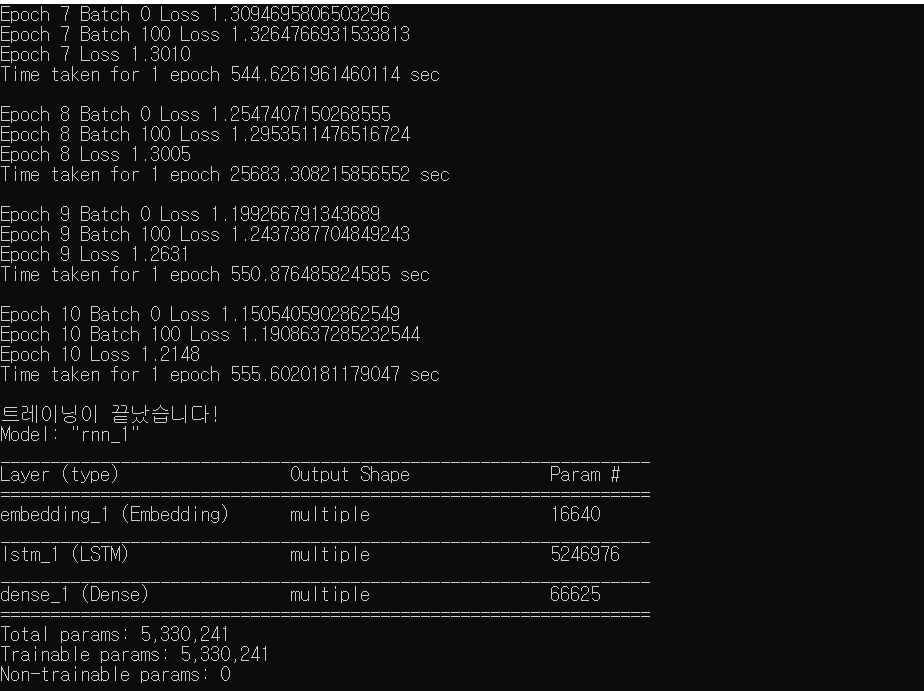

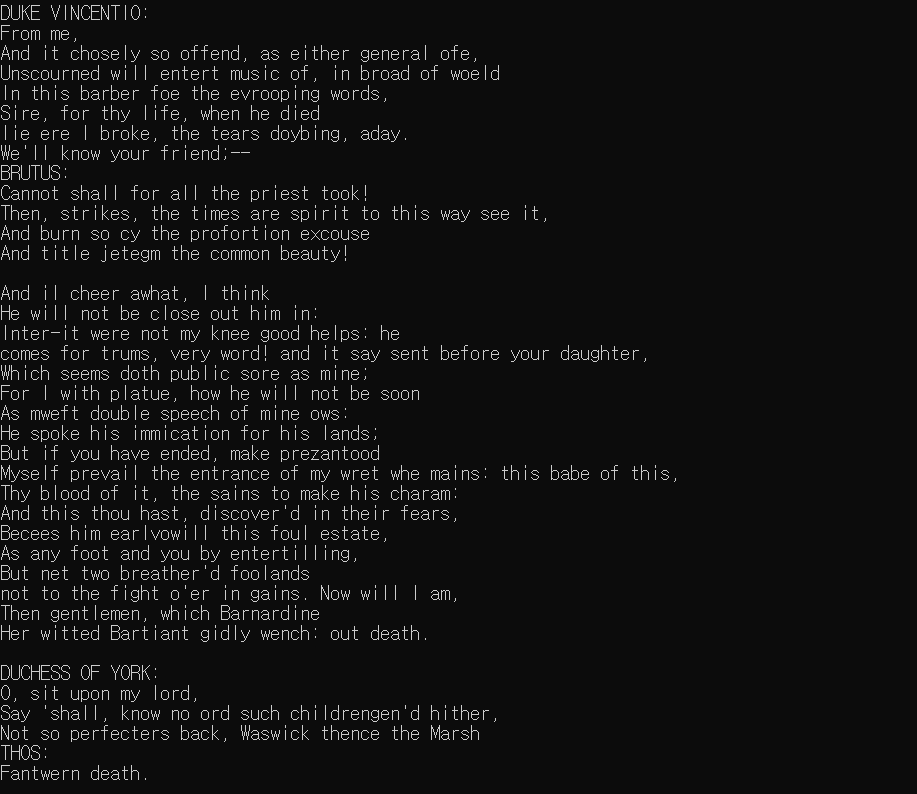
셰익스피어의 희곡을 학습한 후 RNN 모델이 새로운 희곡을 작성한 결과이다.
한 눈에 봐도 그럴듯한 텍스트를 생성해낸 모습을 볼 수 있다.
자세히 보면 단어의 구성과 흐름은 말이 안되지만 희곡의 글자 배열 등 구조적으로 그럴듯한 모습을 띈다.
'Study > Deep Learning' 카테고리의 다른 글
| Object Detection by Haar cascade (0) | 2021.11.10 |
|---|---|
| Gradient Clipping (0) | 2021.10.20 |
| Embedding (0) | 2021.10.20 |
| 순환신경망(RNN) (0) | 2021.10.19 |
| Pre-Trained CNN 모델을 이용한 Image Classification (0) | 2021.10.18 |