tf.keras.applications 모듈을 이용한 VGGNet의 Fine-Tuning을 통한 Cats vs Dogs Dataset 분류
kaggle에서 제공하는 Cats vs Dogs 데이터셋을 이용해 이 둘을 분류해내는 예제이다.
https://www.kaggle.com/c/dogs-vs-cats
Dogs vs. Cats | Kaggle
www.kaggle.com
아래는 Google colab으로 작성된 글이다.

먼저 필요한 라이브러리들을 import하는 과정이 필요하다.
그리고 나중에 이미지 사이즈를 160x160으로 고정하기 위한 전역변수 IMG_SIZE를 선언한다.
format_example 함수 부분
tf.cast.(image, tf.float32) : 이미지를 인풋으로 받고, float 형태로 변환
image = (image / 127.5) -1 : 이미지를 [-1, 1]로 정규화. 이미지 데이터 실수 범위를 -1에서 1 사이로 만들어 줌
그 후 이미지 사이즈 재조정하는 부분이 나온다.

Cats vs Dogs 데이터셋을 다운받고 불러오는 과정이다.
tensorflow dataset(tfds)에 이미 'cats_vs_dogs'라는 이름으로 데이터셋이 저장되어 있기 때문에 저렇게 간단히 다운로드 할 수 있다.
80%는 training data, 10%는 validation(확인) data, 나머지 10%는 test data로 사용하기 위해 3부분으로 나눠 불러온다.

label 이름들은 metadata에서 label이라는 컬럼에 있으니
이를 가져오고, 문자열로 바꿔주는 과정이 필요하다.
그리고 확인해본다.
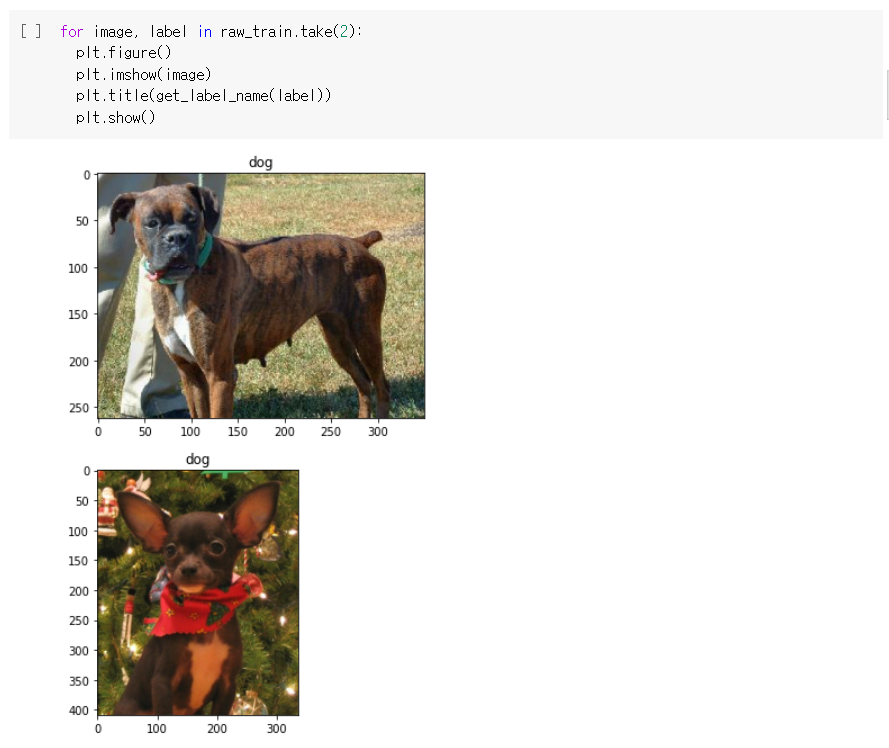
첫 번째 나눴던 부분 raw_train에서 2개의 이미지를 불러와 확인해보는 과정이다.
plt.figure() : figure()함수를 불러냄
imshow()로 이미지를 불러오고, title()로 그에 맞는 label을 제목으로 지정한다.
그리고 show()로 화면에 출력한다.

여기까지가 사전 학습된 모델 데이터를 전처리하는 코드였다.

이미지 사이즈를 지정하고
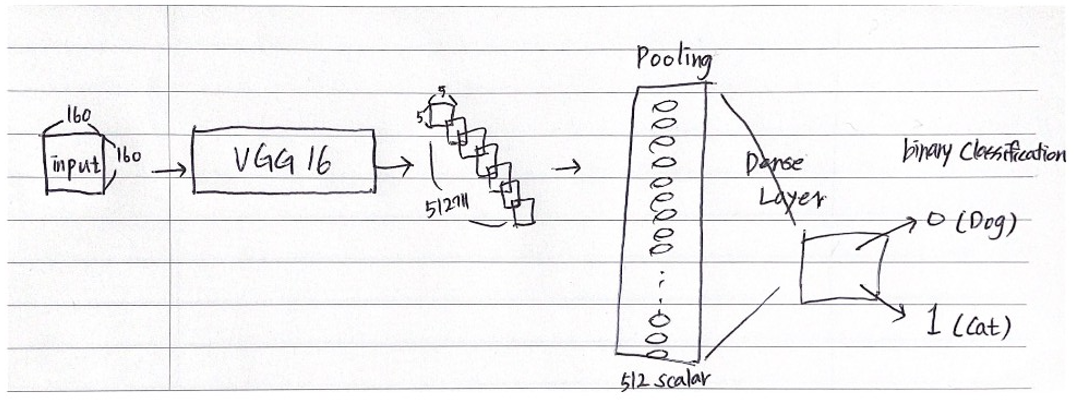
사전 학습 model을 'VGG16' 모델로 지정한다.
input 이미지는 160x160, 3개에서 VGG16을 거치게 되면서 5x5, 512개로 변환됨을 알 수 있다.
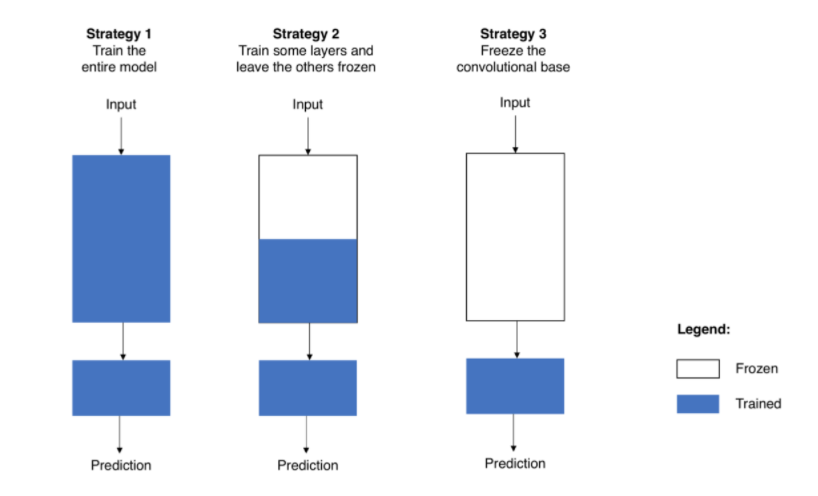
그리고 trainable = False로 지정함으로써 전체 파라미터를 frozen 상태로 정한다. (Fine-Tuning 세 번째 전략)

VGG16의 구조를 살펴보면 위의 형태와 같다.
두 번째 실습에선 block5_con1, block5_con2, block5_con3 부분까지 Fine-Tuning 범위로 지정할 것이다.



초기 loss 값과 정확도를 측정해본다.

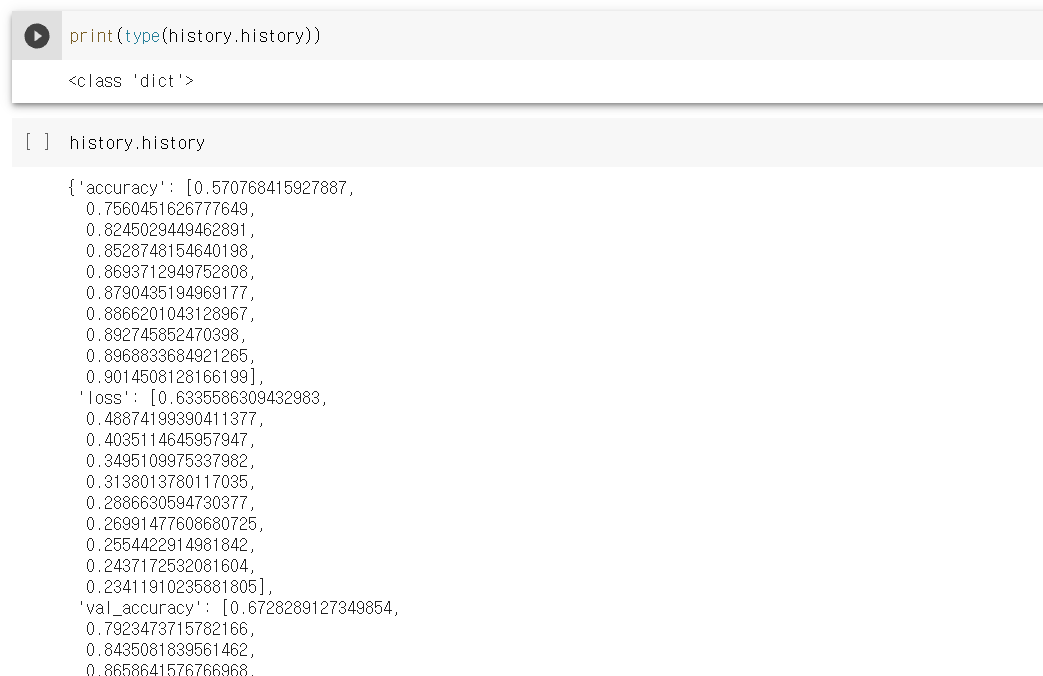
history는 dict 형태로 저장되어 있는 것을 알 수 있다

이를 우리가 사용할 변수명으로 바꿔준다.


첫 번째 학습 결과를 시각화해본다.
10번의 epoch 동안의 training data와 validation data의 정확도와 손실함수 값 변화가 나타난다.

현재 base_model은 19층으로 이루어져 있다.
block5_conv1층부터 학습하는 것으로 fine-tuning 하기 위해 위와 같은 과정을 거친다.

앞서 진행했던 것과 같이 BinaryCrossentropy를 손실함수로 정해주고
기존 learning rate가 0.0001 이었지만 이를 0.00001로 다시 지정해주면서 정확도를 높이고자 한다.



기존 방식으로 10번 학습한 후, 두 번째 Fine-Tuning이 적용된 방식으로 10번 학습한다.
정확도가 매우 높아지며 손실함수 값은 작아지는 것을 확인할 수 있다.
'Study > Deep Learning' 카테고리의 다른 글
| Embedding (0) | 2021.10.20 |
|---|---|
| 순환신경망(RNN) (0) | 2021.10.19 |
| Fine-Tuning(Transfer Learning) (0) | 2021.10.18 |
| TensorBoard 이용하기 (0) | 2021.10.18 |
| tf.train.CheckpointManager API (0) | 2021.10.18 |