<머신러닝의 기본 프로세스 - 가설 정의, 손실함수 정의, 최적화 정의 >
① 학습하고자 하는 가설(Hypothesis) h(θ) 을 수학적 표현식으로 나타낸다
② 가설의 성능을 측정할 수 있는 손실함수(Loss Function) J(θ)을 정의한다
③ 손실함수 J(θ)을 최소화(Minimize)할 수 있는 학습 알고리즘을 설계한다
1. 가설 정의
ex) 선형 회귀 모델
y = Wx + b
x = 인풋 데이터 / y = 타겟 데이터 / W와 b는 파라미터(θ)
2. 손실함수 정의
: 적절한 파라미터 값을 알아내기 위해 이 과정이 필요
ex) 평균제곱오차(Mean of Squared Error, MSE)
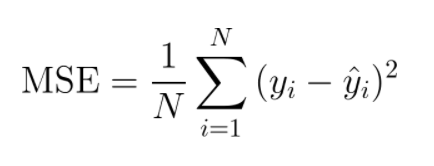
yi = 정답값
y^i = 예측값
모델의 예측값이 정답과 멀다면 MSE 손실함수는 큰 값을 가지게 되고 정답에 가깝다면 MSE 손실함수는 작은 값을 갖게 됨
이처럼 손실 함수는 우리가 풀고자 하는 목적에 가까운 형태로 파라미터가 최적화 되었을 때(모델이 잘 학습되었을 때) 더 작은 값을 갖는 특성을 가짐
따라서 손실함수를 "비용 함수(Cost Function)"라고도 부름
3. 최적화 정의
최적화Optimization 기법 = 파라미터를 적절한 값으로 업데이트 하는 알고리즘
대표적인 기법 = Gradient Descent (경사하강법)
Gradient Descent
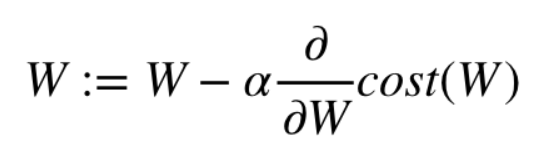
: 현재 스텝의 파라미터W에서 손실함수(cost)의 미분값에 러닝레이트(Learning rate) α 를 곱한만큼을 빼서 다음 스텝의 파라미터 값으로 지정
+ 학습률(Learning rate) = W에 변화를 주는 정도
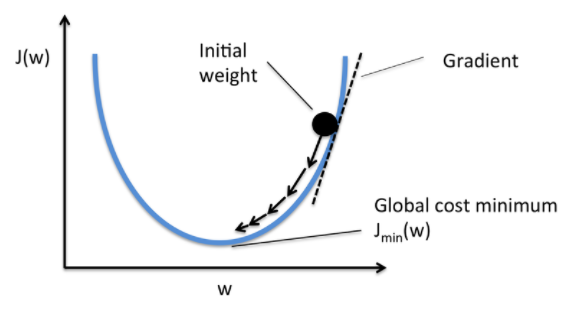
따라서 손실 함수의 미분값이 크면 하나의 스텝에서 파라미터가 많이 업데이트 되고
손실 함수의 미분값이 작으면 적게 업데이트 됨
또한 러닝레이트α 가 크면 많이 업데이트되어 반복횟수가 줄어들고
러닝레이트α 가 작으면 적게 업데이트되어 반복횟수가 늘어난다.
+ Batch Gradient Descent, Stochastic Gradient Descent, Mini-Batch Gradient Descent
위에서 살펴봤던 경사하강법은
트레이닝 데이터 n개의 손실함수 미분값을 모두 더한 뒤 평균을 취해서 파라미터를 한 스텝 업데이트 하는 방법이었다.
이런 방법을 전체 트레이닝 데이터를 하나의 Batch로 만들어 사용하기 때문에 Batch Gradient Descent 라고 부른다.
---> 트레이닝 데이터가 많아지면 파라미터를 한 스텝 업데이트하는데 많은 시간이 걸린다는 단점이 있다!
이와 반대로, Stochastic Gradient Descent 방법은 1개의 트레이닝 데이터만 사용하는 기법이다.
---> 파라미터를 자주 업데이트할 수 있지만 전체 트레이닝 데이터의 특성을 고려하지 않고 각각의 트레이닝 데이터의 특성만을 고려하므로 부정확한 방향으로 업데이트가 진행될 수 있다.
따라서, 실제 문제를 해결할 때는 이 둘의 절충적 기법인 Mini-Batch Gradient Descent 를 많이 사용한다.
전체 트레이닝 데이터 Batch가 1000(n)개라면 이를 100(m)개씩 묶은 Mini-Batch 개수만큼의 손실 함수 미분값 평균을 이용해서 파라미터를 한 스텝 업데이트 하는 기법이다.
'Study > Deep Learning' 카테고리의 다른 글
| 다양한 Computer Vision 문제 영역 (0) | 2021.10.14 |
|---|---|
| 머신러닝 Data 종류 (0) | 2021.10.14 |
| 딥러닝의 응용분야 (0) | 2021.10.13 |
| 머신러닝/딥러닝 기초 (0) | 2021.10.13 |
| 수치 미분 (0) | 2020.11.06 |