- kubectl get pod -o wide --watch - watch kubectl get pod -o wide
Job
: 배치 처리에 적합한 Controller로서 Pod의 성공적인 완료를 보장
: Job을 사용하여 Pod를 실행하면?
Pod의 작업이 정상적 종료 → 완료
Pod의 작업이 비정상적 종료 → 다시 실행시켜 Application의 작업을 하도록 함
전제 : Kubernetes에서 Pod은 항상 Running
실습) Job - wget http://down.cloudshell.kr/k8s/lab/job/job-exam1.yaml - watch kubectl get pod -o wide - kubectl apply -f job-exam1.yaml 60초 동안 sleep 프로세스 진행 중
60초 이내에 pod 종료(비정상적 종료) - kubectl delete pod pod_name 이렇게 하면 다시 생성한다
- kubectl apply -f replicationcontroller.yaml yaml
- kubectl get rc,pod -o wide - kubectl delete pod nginx-g5wrg → 특정 pod 삭제 시 새로운 pod 생성됨 - kubectl run myhttp --image=httpd --labels="app=nginx" --port 80 - kubectl get rc,pod -o wide --show-labels 새로 만들어진 pod는 알아서 종료된다.
- kubectl edit rc nginx → pod의 이미지, 갯수 등 다시 설정할 수 있다.
- kubectl delete rc nginx → Replication Controller 삭제 시 Pod도 삭제됨!! - kubectl delete rc nginx --cascade=orphan → Replication Controller만 삭제되고 Pod는 그대로 유지
ReplicaSet
: Replication Controller와 동일한 역할
차이점은 Replicaion Controller보다 더 많은 selector를 가진다는 점이다.
: Deployment를 생성하면 자동으로 ReplicaSet과 Pod이 생성됨 (Deployment를 삭제하면 자동으로 전부 삭제됨)
: Pod의 Rolling Update 및 Rolling Back 을 위해 주로 사용
실습) Rolling Update - wget http://down.cloudshell.kr/k8s/lab/deployment/deployment-v1.yaml - kubectl apply -f deployment-v1.yaml --record(--record: 업데이트 과정을 history로 기록) - kubectl rollout history deployment app-deploy deployment의 history를 볼 수 있다. - kubectl set image deploy app-deploy myweb-con1=nginx:1.15 --record - kubectl get pod → pod가 하나씩 순서대로 Update 된다 - kubectl describe pod (pod명) 이미지 업데이트 적용 - kubectl set image deploy app-deploy myweb-con1=nginx:1.16 --record - kubectl set image deploy app-deploy myweb-con1=nginx:1.17 --record
- kubectl rollout history deployment app-deploy history 확인 - kubectl rollout undo deploy app-deploy undo 결과 - kubectl rollout undo deploy app-deploy --to-revision=2 → 특정 단계로 돌아간다
: 상태를 유지하는 항목 ▶ Pod 이름을 순서대로 명명(0~N), Pod의 Volume(PVC 이름), Network (Headless Service)
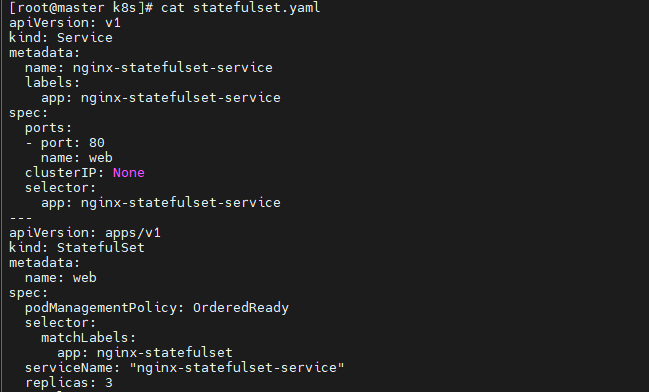
※ 주의 ※ StatefulSet 생성 시 yaml 파일에는 serviceName, replicas, podManagementPolicy, terminationGracePeriodSeconds이 반드시 포함되어야 한다
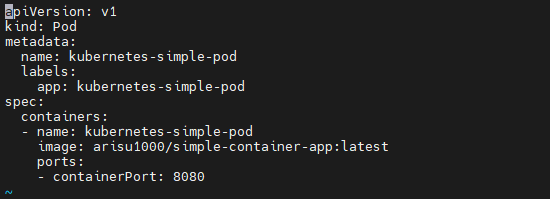
yaml 일부
- kubectl apply -f statefulset.yaml
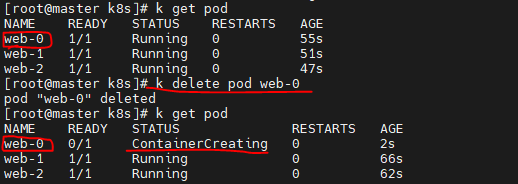
StatefulSet으로 Pod이 생성된 경우에는 Pod이 삭제되면 이전의 삭제된 Pod의 이름과 동일한 Pod이 생성된다.
실습) StatefulSet의 rollingUpdate.partition 수정하기 : StatefulSet에 변경사항이 있을 때 rollingUpdate.partition에서 지정한 값보다 작은번호의 Pod은 변경되지 않고 크거나 같은 번호만 변경시킨다 : 서버 패치할 때 등의 경우에 사용한다
- kubectl apply -f statefulset.yaml (## web-0, web-1, web-2가 실행되고 있음) - kubectl edit statefulset web image를 nginx에서 nginx:1.14로 변경partition 부분을 0에서 2로 변경
- kubectl get statefulsets.apps
2보다 작은 0과 1은 계속 동작하고 2만 수정된다.
Deployment, DaemonSet, StatefulSet의 공통점과 차이점
ⓐ 공통점
Rolling update 및 Rollback 가능
각각을 삭제하면 Pod도 동시에 삭제됨
ⓑ 차이점
Deployment - Pod이 어떤 Node에 생성될 지 예측 불가
DaemonSet - Node별로 동일한 Pod이 하나씩 생성
StatefulSet - serviceName 필요 - Pod 이름 및 볼륨 유지 - partition 값에 따라 업데이트 되지 않을 Pod을 지정할 수 있음
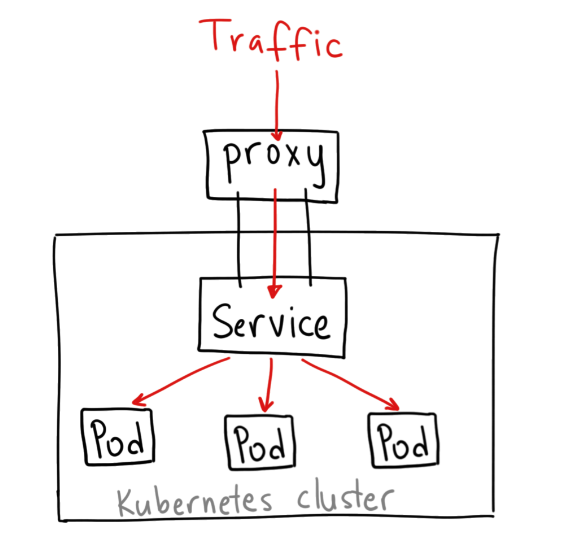
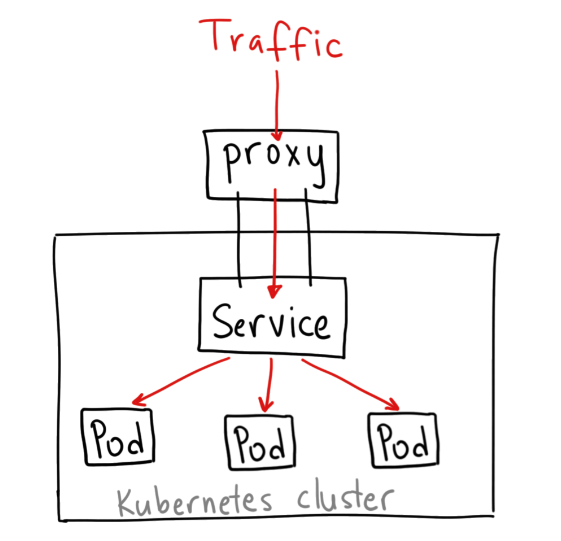
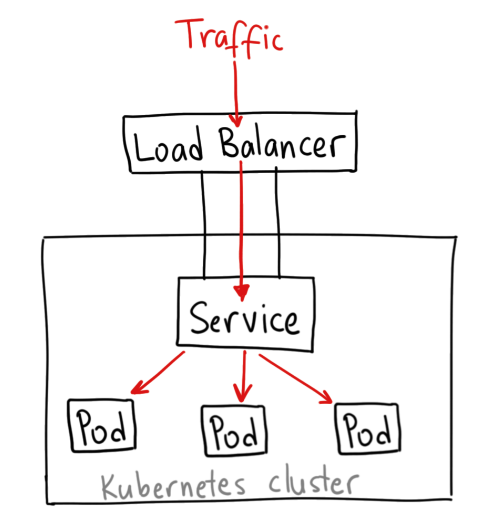
동일한 서비스를 제공하는 여러 개의 Pod에 접근할 수 있는 하나의 IP를 제공 (Service 자신이 갖고 있는 Selector 값과 Cluster에서 운영중인 Pod의 Label 값이 동일한 Pod으로 연결된다. Service는 자신의 EndPoint에 Pod를 추가시켜 관리한다.)
추가) kubectl run으로 pod 생성 후, Service도 생성했는데 오류가 나는 경우
→ pod의 labels 값과 service의 selector 값을 비교해볼 필요가 있다.
※ Pod의 Labels 값 확인
- kubectl get pod -o wide --show-labels
※ Service 내부 설정 정보 확인
- kubectl edit service 서비스명
Service는 Pod에 연결시켜주는 Network
어느 Service 유형이든 결국 Cluster IP를 통해 Pod에 접근 (Pod는 기본적으로 한 Node에서만 실행되지 않고 상황에 따라 Cluster내에 속한 여러 Node로 옮겨다닌다. 그러므로 Pod의 IP로 접속하는 데는 한계가 있고 동일한 서비스의 대표 IP인 Service의 IP로 접근하는 것이 편리하다.)
Service 종류
1. ClusterIP
: Default Service로서 Pod들이 클러스터 내부의 다른 리소스들과 통신할 수 있도록 해주는가상의 클러스터 전용 IP
(IP는 Container에는 없고 Pod 에만 있다. Pod IP는 변경이 가능하므로 변경되지 않는 Virtual IP를 갖는 Service를 사용해야 한다)
: Cluster 내에서 Pod에 접속할 때는 Cluster IP를 이용한다.(Pod는 언제든지 죽고 다시 생성되어 IP가 변경되기 때문)
: Cluster IP로는 Cluster 내부에서만 접속할 수 있다.
: ClusterIP → Pod
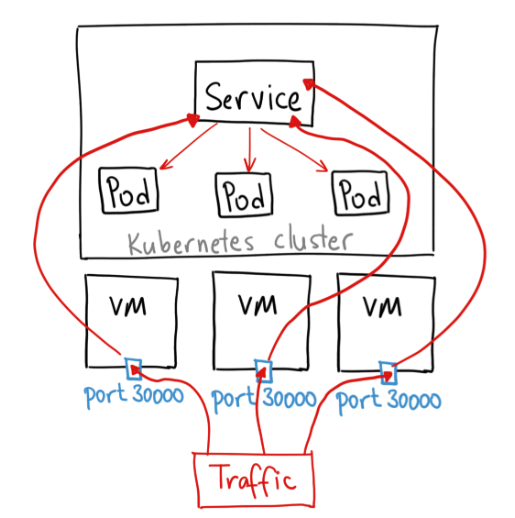
2. NodePort
: 외부에서 노드 IP의 특정 포트(<NodeIP>:<NodePort>)로 들어오는 요청을 감지하여, 해당 포트와 연결된 파드로 트래픽을 전달하는 유형의 서비스다.
: 이때 클러스터 내부로 들어온 트래픽을 특정 파드로 연결하기 위한ClusterIP역시 자동으로 생성된다.
: Cluster 내의 아무 Node의 IP에 대한 Port 번호로 접속하도록 한다.
(30,000 ~ 32,767 포트 사용)
: NodePort → ClusterIP → Pod
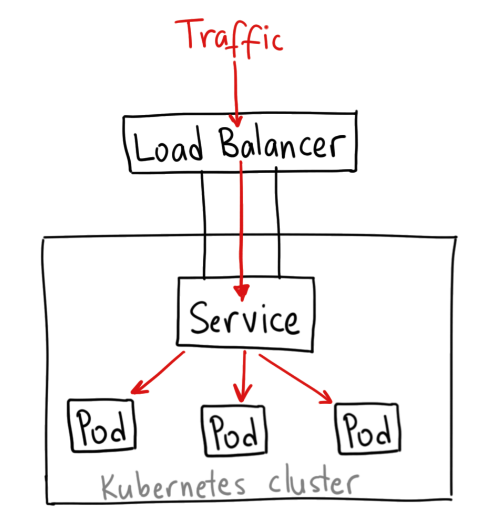
3. LoadBalancer
: Layer2 ~ Layer4를 지원하는 부하조정 장비 (domain은 Layer7의 Ingress Controller가 처리)
: 클라우드 공급자(Public Cloud)의 로드 밸런서, 외부 장비, Metallb를 사용하여 서비스를 외부에 노출시킨다.
: 외부 로드 밸런서가 라우팅되는NodePort와ClusterIP서비스가 자동으로 생성된다.
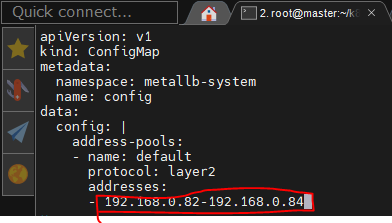
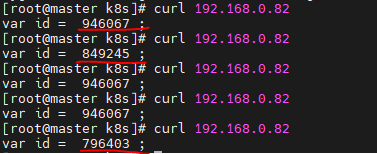
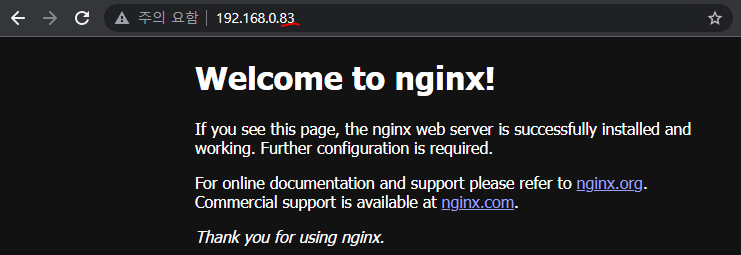
: OnPoremises(사내)에서는 외부 LB 장비를 이용하거나 그것보다는 k8s의 Metallb라는 Load Balancer를 이용한다.
Metallb에 사용할 Secret 생성 - kubectl create secret generic -n metallb-system memberlist --from-literal=secretkey="$(openssl rand -base64 128)"
** 외부에서 접속할 때 사용되는 IP생성을 위해 ConfigMap 생성 ** - wget http://down.cloudshell.kr/k8s/ConfigMap-Metallb.yaml - vi ConfigMap-Metallb.yaml (## 원하는 대역으로 수정 (기본IP 구성은 10.0.2.200-10.0.2.250인데 사내에 맞게 수정)) - kubectl apply -f ConfigMap-Metallb.yaml ▷ 이제 Load Balancer에 이 IP를 할당한다
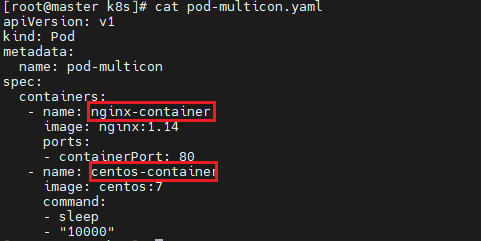
Pod Object 특징 : 1개의 pod는 내부에 여러 개의 컨테이너를 가질 수 있지만 대부분 1~2개의 컨테이너를 갖는다. = "고래(Containers)들의 떼"
: 클러스터 내에서 사용할 수 있는 고유한 IP 주소를 할당 받지만, 이 ip는 Service에서 사용하지 않는다. : Pod의 외부에서는 'Service'를 통해 Pod에 접근한다.(Service가 Pod의 Endpoint를 관리한다.) : Pod 내부의 컨테이너들은 네트워크와 볼륨등을 공유하고 서로 localhost로 통신할 수 있다.
상태(State) 관리 : 설정한 Pod 개수 보장,Pod의 livenessProbe(컨테이너가 동작 중인지 여부를 나타낸다. 만약 활성 프로브에 실패한다면, kubelet은 컨테이너를 죽이고, 해당 컨테이너는재시작 정책의 대상이 된다.)
부하 조정(Scheduling)으로 배포 관리 : Pod 배포 시 부하 정도가 가장 적절한 node 선정하여 배포
배포 버전 관리 : Rolling Update (Deployment로 새로운 버전의 App을 이전 버전을 유지한 채 업데이트 진행) + Roll Back (문제 발생 시 이전 버전으로)
Service Discovery (Pod 집합에서 실행중인 Application을네트워크 서비스로 노출하여 Cluster 외부에 있는 User가 Application을 이용하도록 네트워크 경로를 제공하는 것) (K8S는 Pod에게 고유한 IP주소 부여, Pod 집합에 대한 단일 DNS명을 부여.이들간의 로드-밸런싱 수행)
Volume Storage (각 node 별 다양한 storage 제공) (Volume : Pod에 종속되는 디스크. 해당 Pod에 속해 있는 여러 개의 Container가 공유해서 사용)
Kubernetes는 서비스 관리를 개별적이 아닌 집단적으로 관리한다
따라서 대부분의 상황에서 개별 시스템(node)와 상호작용할 필요는 없다
→ 비교적 Stateless(관계의 상태를 유지하지 않는 것) 업무에 적합하다 (stateless 예시 : UDP 프로토콜)
개발 배경
Container는 stateless, immutable, mortal (상태를 가지고 있지 않고, 변화하지 않으며, 언제든 죽을 수 있는)개념을 기반으로 아키텍처를 구성하다 보면 운영에 앞서 반드시 필요한 것이 Container Orchestration(=Kubernetes)이
Container Orchestration은 다수의 Container를 다수의 node(Cluster)에 적절하게 분산 실행하고, 원하는 상태(Desired State)로 실행상태를 유지해 주고, 다운타임 없이 유동적으로 스케일을 확장/축소(Scale)할 수 있게 도와준다
사용자가 Container에 대한 동작과 다른 Container와의 관계를 정의하면 배포/운영/스케일링에 문제가 없도록 자동으로 관리되는 운영 시스템이라고 할 수 있다
Kubernetes 종류
관리형 Kubernetes : Amazon EKS, Azure AKS, Google GKE
설치형 Kubernetes : RANCHER, RedHat OPENSHIFT
직접 구성형 Kubernetes : Kubeadm, Kubespray, Kops, Krib
Kubernetes 설치
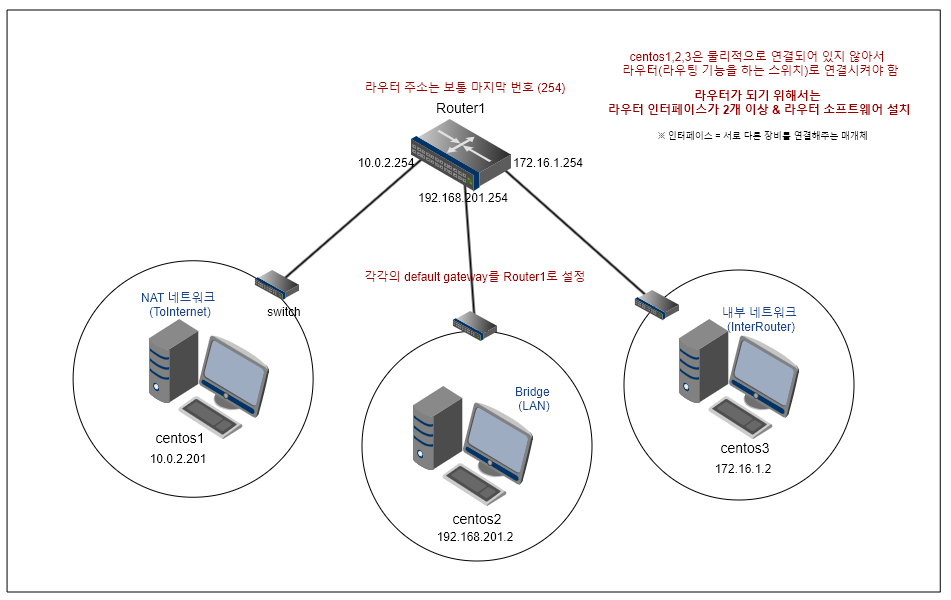
설치 구성도
(아래 내용은 master, node1, node2, node3 모두에게 적용)
실행 환경 : centos7-x86_64
1. /etc/hosts 파일 수정
/etc/hosts
각 PC의 IP 작성 후 scp 로 node1,2,3에 복사 - scp /etc/hosts node1:/etc/hosts
2. SWAP 기능 끄기 - swapoff -a - vi /etc/fstab (마지막 부분인 swap 부분 주석처리) - reboot
6. docker 설치 및 시작 - curl -sSL http://get.docker.com | bash - systemctl start docker && systemctl enable docker - docker info | grep -i cgroup (이 명령어 입력 시 Cgroup Driver : cgroupfs라고 나타난다. Kubernetes는 docker의 cgroup을 systemd를 사용하기 때문에 이를 systemd로 변경해주어야 한다)
7. docker cgroup driver를 systemd로 변경 - vi /usr/lib/systemd/system/docker.service (ExecStart=/usr/bin/dockerd 바로 뒤에 --exec-opt native.cgroupdriver=systemd를 삽입) - systemctl daemon-reload (## 모든unit file을reload) - systemctl restart docker - docker info | grep -i cgroup(## systemd로 변경됨)
9. K8S Clustering 구성(Master에서만 작업) #특정한 이전 버전(1.21.1)의 K8S Clustering 구성 - kubeadm init --kubernetes-version=v1.21.1 이때, 설치 결과를 복사하여 다른 곳에 꼭 저장해놓는다. ----------------------------------------------------------------------------
설치 결과 Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
10. Kubernetes 버전 정보 확인 - Master에서 - kubectl version --short - kubeadm version -o yaml - kubelet --version
레파지토리 버전 정보
Namespace 확인 - kubectl get namespaces
- kubectl get namespace
- kubectl get ns
11. Cluster 구성정보(ConfigMap) 확인하기 - Master에서 - kubectl get configmap -n kube-system - kubectl get cm kubeadm-config -n kube-system - kubectl get cm kubeadm-config -n kube-system -o yaml - kubeadm config view
12. Clustering 상태 및 Pod 상태 확인하기 - Master에서 - kubectl get node (## master가 NotReady 상태) - kubectl get pod --all-namespaces (## 모든 pod 확인) - kubectl get pod -A (## 모든 pod 확인)
-->> cluster 상태가 Not Ready이고 coredns 상태가 Pending이다.
이 상태에선 각 Node들에서 실행중인 Pod들간에 통신이 안된다 -->>Pod Network를 생성하여 이 문제를 해결할 수 있다
13. Pod Network 구성하기 - Master에서만 작업 (weave-net 설치) - export kubever=$(kubectl version | base64 | tr -d '\n') - kubectl apply -f "https://cloud.weave.works/k8s/net?k8s-version=$kubever"
- kubectl get pod -A (## coredns가 이제는 running) 30초 정도 기다린 후 - kubectl get pods -A
weave - net - xxxxx 이라는 Pod 이 master 에 설치됨
- kubectl get nodes (## master가 Ready 상태가 됨)
(node1,2,3에서) kubeadm join 10.0.2.15:6443 --token h1a03j.qe1qctd831cfijxa \ --discovery-token-ca-cert-hash sha256:538ab8cea29bab9814f850a87450008bf8ee7efcf3706e562bbc6ce5bb08cf74 입력 후
(master) - kubectl get nodes (## master 말고 node1,2,3도 Ready 상태가 됐음을 알 수 있다)
container layer = 컨테이너가 작업하는 데이터 저장. 따라서 컨테이너 종료 시 conatiner layer 삭제됨
컨테이너가 실행되면 ImageLayer를 참조하여 Container Layer를 생성 •결과적으로 2종류의 Layer가 생성되고, 이 두 Layer를 합친 것이 바로 컨테이너의 File System •그래서 Container의 File System을 Union File System이라고 한다
• Docker Image Layer
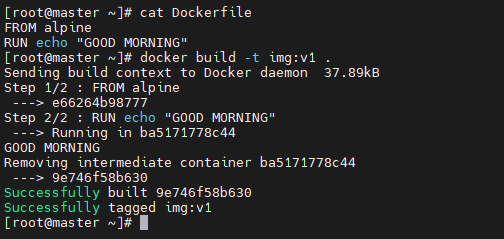
: Docker Image Layer는 Dockerfile 명령어 갯수와 동일
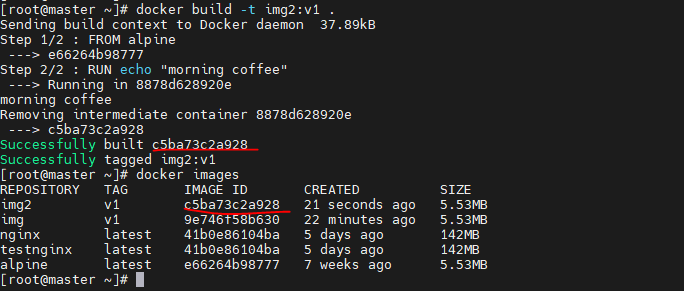
Dockerfile 내용Image Layer가 두개 있고, 이를 합쳐 최종적으로 Image 생성(9e74~)생성된 이미지 확인((9e74~)docker image history img:v1docker inspect img:v1
image layer를 보여주는 docker inspect와 docker history는 보여지는 image layer 갯수가 다를 수 있다
(docker inspect에서는 image layer 크기가 0인 것은 보여주지 않음)
※ 먼저 생성된 Layer는 다음에 생성된 Layer의 부모(Parent)가 된다
• Build Cache
docker build를 실행할 때 사용되는 개념.
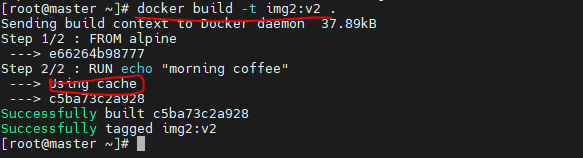
Build 중에 동일한 Image Layer가 있으면 기존 것을 재사용한다는 개념
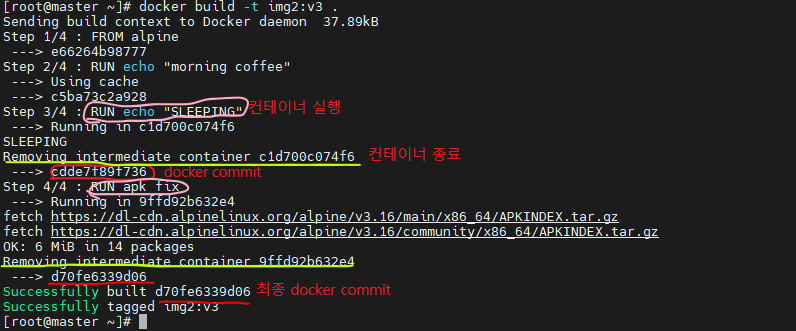
img:v2 빌드Dockerfile 내용 수정 없이 다시 build. Cache 사용함을 알 수 있다.Dockerfile 수정img:v3 빌드. Cache를 사용함과 새롭게 Image가 생성됨을 알 수 있다.
여기서, 수정이 없는 Layer2 까지는 Cache를 사용하지만, 새롭게 입력된 명령어( echo SLEEPING ,,,)에 대해서는 새롭게 작업함을 알 수 있다.
img: v1, v2는 같은 Image ID를 가지지만, v3는 다르다.
따라서, Image Layer 수정이 빈번한 dockerfile명령어는 최대한 마지막에 쓰는 것이 중요 •만약 제일 위에 빈번한 수정이 있는 Image Layer가 있다면, 수정할 때마다 대부분의 Image Layer를새롭게 생성하기 때문에, 그만큼 Build 속도가느리고 Image Layer저장공간을 많이 차지하게 된다
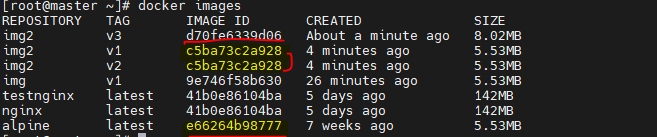
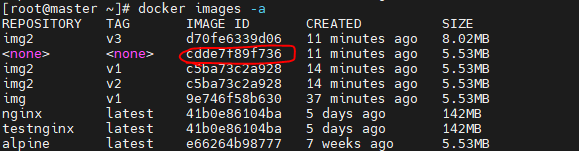
Docker Build 과정docker images -a 명령어를 통해 중간 과정의 이미지 확인
•dangling 이미지 = 이름과 태그가 없는 image
dangling 이미지 종류
1. docker build 과정에서 중간에 생성되어 삭제된 docker image layer = "dangling build cache"
2. 기존 도커 이미지와 동일한 이름과 태그를 사용하여 docker build했을 때 = "dangling image"
dangling 이미지는 불필요하게 디스크 공간을 차지할 수 있으므로 관리자가 수동으로 삭제해야 한다!
- MAC address table 자동 생성 - Transparent Bridging(Learning, Flooding, Forwarding, Filtering, Aging) 1. Learning, Flooding : 주소를 파악, 없으면 Flooding 2. Forwarding, Filtering 3. Aging : 시간이 지나면 알아서 사라짐
스위치끼리 연결하면 ? 네트워크가 확장이 됨 네트워크를 구성하기 위해 기본적으로 필요함 한 네트워크에 최대 500대 권장
스위치도 너무 많으면 충돌이 발생 라우터가 이를 조정. 라우터는 기본적으로 브로드캐스트 차단. 스위치는 기본적으로 브로드캐스팅
라우터 쓰는 목적, 이유
1. Routing & Switching : 길 찾기 2. 거리가 멀어서 3. 네트워크 간 충돌을 줄이기 위해 스위치 중간에 위치하여 대역(네트워크)을 나눠 원활하게 통신. (브로드캐스팅 차단) 4. 보안(패킷 필터링으로 차단)
단점 : 속도 저하(잘 못 느낌) -> 해결 : 라우터 대신 L3 스위치 사용(LAN 라우터. 속도 안떨어짐)
종단 라우터는 default gateway 무조건 필요. 중간에 있는 애들은 설정 안 해도 됨.
- tracert(traceroute) : 라우터 경로 추적하는 명령어, 고장난 라우터 찾을 수 있음
공인 IP
공인 IP는 전세계에서 유일한 IP 주소
사설 IP
하나의 네트워크 안에서 유일
사설 IP 주소만으로는 인터넷에 직접 연결할 수 없다. 라우터를 통해 1개의 공인(Public) IP만 할당하고, 라우터에 연결된 개인 PC는 사설(Private) IP를 각각 할당 받아 인터넷에 접속할 수 있게 된다. --> 이 정보를 NAT Table에 저장
------------------------------------ <용어 정리>
L2 : 스위치 - VLAN.. VLAN(Virtual LAN) - 하나의 Switch에 연결된 장비들의 Network(Broadcast Domain)를 나눔 - 사용 시, 보안성 강화(라우터로 통신해야 하기 때문에)
L3 : 라우터 포함 스위치 - VPN..
1. 포트 포워딩
- 공유기(라우터)에서 진행 - 특정 포트(모든 포트)를 통해 목적지를 지정해 줌
포트 포워딩
외부(10.0.2.202)에서 각각에 접속
2.Reverse Proxy
- 웹 서버 앞에 위치하여 - 웹 서버(80,443)에 대해서만 포워딩 - "L7 스위치" - 리버스 프록시 서버를 여러개의 서버 앞에 두면 특정 서버가 과부화 되지 않게 로드밸런싱이 가능
- 클라이언트 앞에 위치하여 클라이언트가 자신을 통해서 다른 네트워크 서비스에 간접적으로 접속할 수 있게 해 주는 컴퓨터 시스템이나 응용 프로그램 - 일반 프록시 서버
4. 로드 밸런서
- 여러 대의 서버를 두고 서비스를 제공하는 분산 처리 시스템에서 필요한 기술 - 똑같은 storage. 다른 contents. DNS 서버의 단점을 해결한 장비 - 보안을 위해서 사용 - "L4 스위치"
*포트포워딩 접속 시 비밀번호가 필요 없음 * VPN 접속 시 사용자 비밀번호 필요
-----------------------------------
한 주소에 여러 접속 요청이 있을 시(부하 상황 발생), 어떻게 할까? "스케일 아웃" : 장비를 추가해서 확장하는 방식(주소(url)는 같고 IP는 다르게. 무한 분산 방식)
1) DNS Server : 라운드 로빈 방식(첫 번째 요청은 첫 번째 서버, 두 번째 요청은 두 번째 서버, 세 번째 요청은 세 번째 서버에 할당) 문제점 : 부하가 걸리는지 체크할 수 없음 2) Load Balancer : DNS Server의 문제점 해결. 지능적으로 여러 서버가 분산 처리 하는 것