# 텐서보드 summary 정보들을 저장할 폴더 경로를 설정하고 FileWriter를 선언
# trainig 과정에서 발생되는 log를 저장하기 위한 것과 test 과정에서의 log를 저장하기 위한 것을 따로 지정
train_summary_writer = tf.summary.create_file_writer('./tensorboard_log/train')
test_summary_writer = tf.summary.create_file_writer('./tensorboard_log/test')
# 최적화를 위한 function을 정의
@tf.function
def train_step(model, x, y):
with tf.GradientTape() as tape:
y_pred, logits = model(x)
loss = cross_entropy_loss(logits, y)
# 매 step마다 tf.summary.scalar, tf.summary.image 텐서보드 로그를 기록
with train_summary_writer.as_default():
tf.summary.scalar('loss', loss, step=optimizer.iterations) # loss라는 이름으로 현재 iteration time step의 loss값 저장
x_image = tf.reshape(x, [-1, 28, 28, 1]) # flattening된 상태 (784차원)를 다시 28x28 gray scale 이미지로 저장
tf.summary.image('training image', x_image, max_outputs=10, step=optimizer.iterations) # training image라는 이름으로 그 시점에서 뽑힌 랜덤 배치의 mnist 트레이닝 이미지 저장. 저장 크기는 최대 10개로 지정
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
# 모델의 정확도를 출력하는 함수를 정의
@tf.function
def compute_accuracy(y_pred, y, summary_writer): # 정확도 측정함수 인자값에 summary_writer 추가
correct_prediction = tf.equal(tf.argmax(y_pred,1), tf.argmax(y,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
with summary_writer.as_default():
tf.summary.scalar('accuracy', accuracy, step=optimizer.iterations)
return accuracy
# Convolutional Neural Networks(CNN) 모델을 선언
CNN_model = CNN()
# 10000 Step만큼 최적화를 수행
for i in range(10000):
# 50개씩 MNIST 데이터를 불러옴
batch_x, batch_y = next(train_data_iter)
# 100 Step마다 training 데이터셋에 대한 정확도를 출력
if i % 100 == 0: # 100번의 학습마다 정확도 측정
train_accuracy = compute_accuracy(CNN_model(batch_x)[0], batch_y, train_summary_writer)
print("반복(Epoch): %d, 트레이닝 데이터 정확도: %f" % (i, train_accuracy))
# 옵티마이저를 실행해 파라미터를 한스텝 업데이트
train_step(CNN_model, batch_x, batch_y)
# 학습이 끝나면 학습된 모델의 정확도를 출력. test 데이터셋에 대한 정확도
print("정확도(Accuracy): %f" % compute_accuracy(CNN_model(x_test)[0], y_test, test_summary_writer))
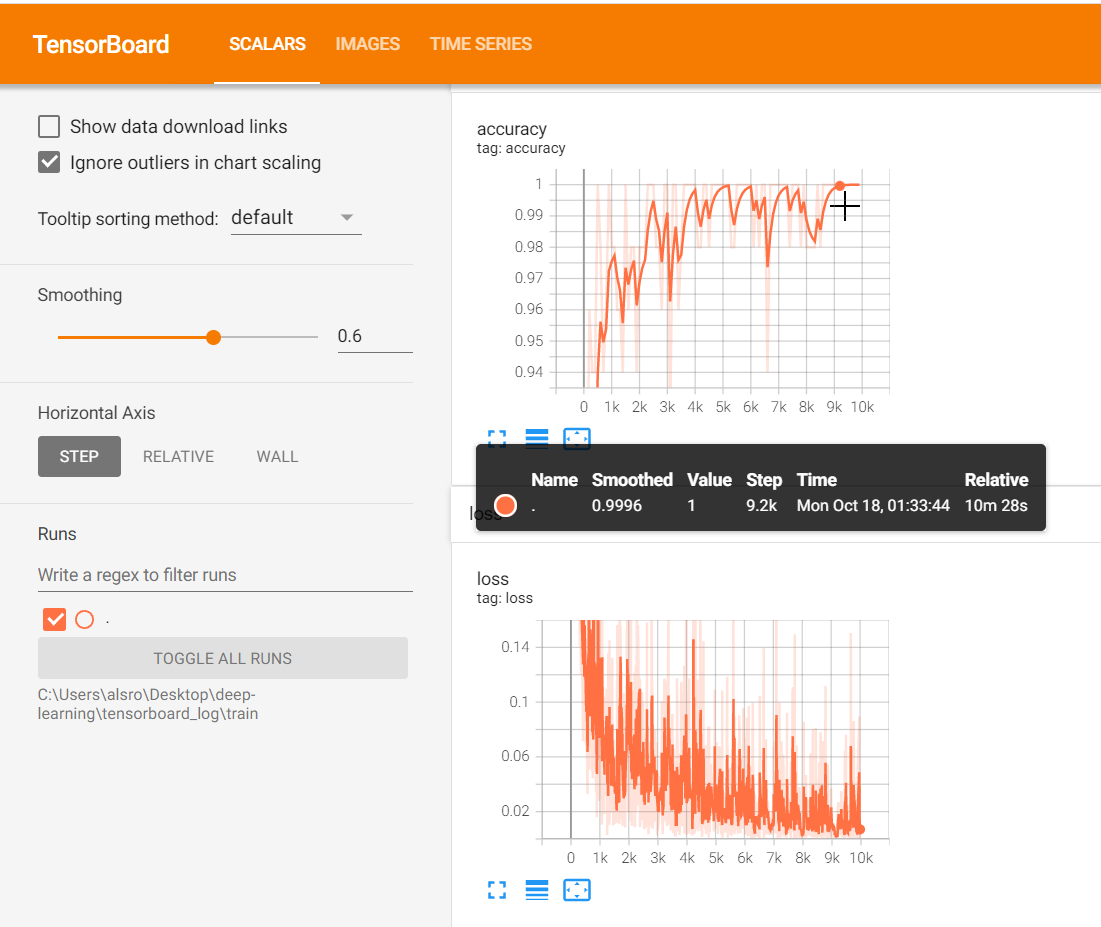
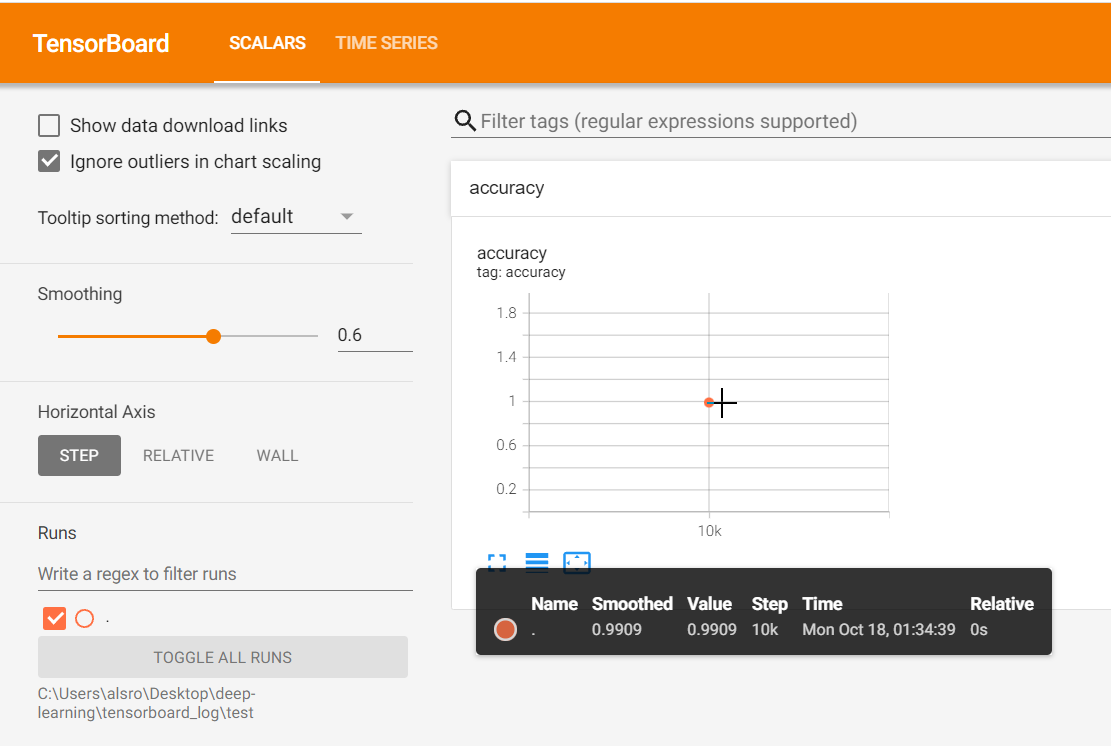
결과파일 생성각각의 데이터셋(training, test)의 Log를 저장하기 위한 파일 생성training 이미지셋에 대한 log를 시각화test 이미지셋에 대한 log를 시각화
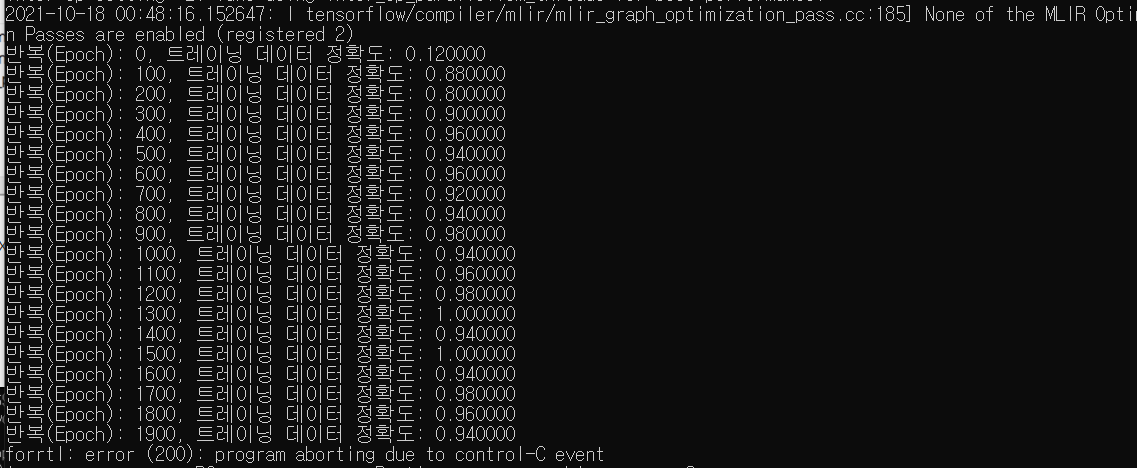
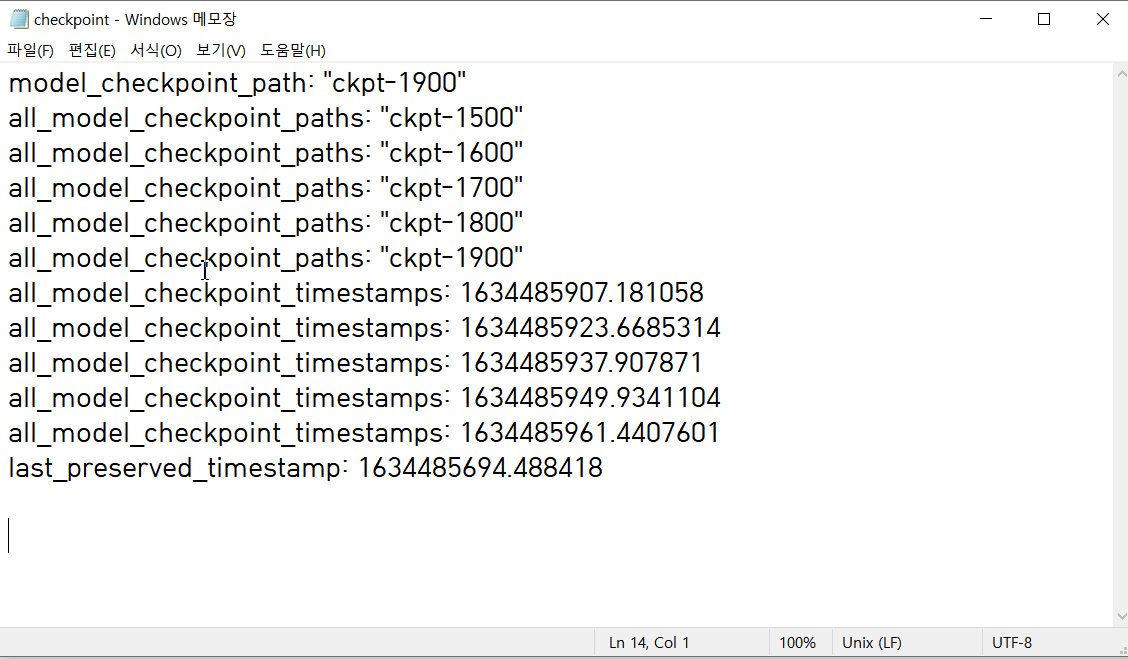
실행 결과, model 폴더가 생성되며, 100번의 학습마다 파라미터 저장 파일들이 생성되었음을 알 수 있고,
1900번 정도의 학습까지만 시키고 끝냈기 때문에 1500부터 1900까지의 학습 파라미터가 저장된 것을 확인할 수 있다.
(최근 5번의 학습결과)
checkpoint라는 이름의 text 파일도 생성되는데, 여기에는 반복횟수에 대한 메타정보 등이 key-value 형태로 들어가 있다.
두 번째 결과
# 만약 저장된 모델과 파라미터가 있으면 이를 불러오고 (Restore)
# Restored 모델을 이용해서 테스트 데이터에 대한 정확도를 출력하고 프로그램을 종료
if latest_ckpt:
ckpt.restore(latest_ckpt)
print("테스트 데이터 정확도 (Restored) : %f" % compute_accuracy(CNN_model(x_test)[0], y_test))
exit()
실행코드 중 이 if문의 마지막 exit() 함수로 인해서 다시 실행하면 이전 학습했던 상태까지의 정확도를 측정한 후 프로그램이 종료됨을 알 수 있다.
# tf.keras.Model을 이용해서 CNN 모델을 정의
class CNN(tf.keras.Model):
def __init__(self):
super(CNN, self).__init__()
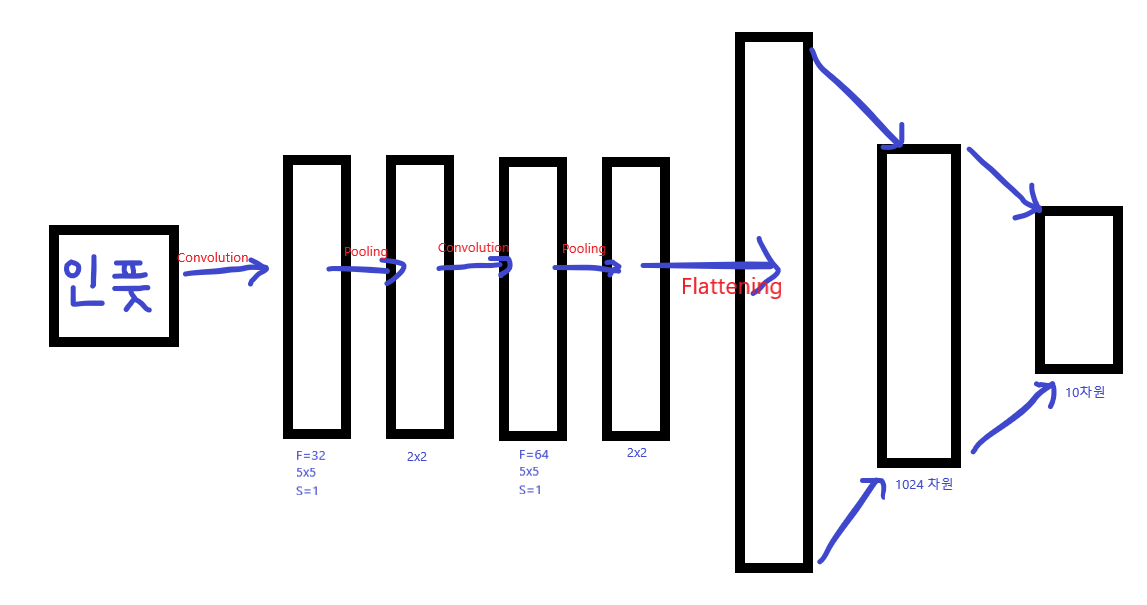
# 첫번째 Convolution Layer
# 5x5 Kernel Size를 가진 32개의 Filter를 적용
self.conv_layer_1 = tf.keras.layers.Conv2D(filters=32, kernel_size=5, strides=1, padding='same', activation='relu')
self.pool_layer_1 = tf.keras.layers.MaxPool2D(pool_size=(2, 2), strides=2)
# 두번째 Convolutional Layer
# 5x5 Kernel Size를 가진 64개의 Filter를 적용
self.conv_layer_2 = tf.keras.layers.Conv2D(filters=64, kernel_size=5, strides=1, padding='same', activation='relu')
self.pool_layer_2 = tf.keras.layers.MaxPool2D(pool_size=(2, 2), strides=2)
# Fully Connected Layer
# 7x7 크기를 가진 64개의 activation map을 1024개의 특징들로 변환
self.flatten_layer = tf.keras.layers.Flatten() #Flattening 수행하는 함수
self.fc_layer_1 = tf.keras.layers.Dense(1024, activation='relu')
# Output Layer
# 1024개의 특징들(feature)을 10개의 클래스-one-hot encoding으로 표현된 숫자 0~9-로 변환
self.output_layer = tf.keras.layers.Dense(10, activation=None)
def call(self, x):
# CNN 같은 경우 인풋 데이터를 Flattening 된 1차원 데이터로 받을 필요가 없음! 따라서 이미지 Dimesion 자체를 인풋으로 받음
# MNIST 데이터를 3차원 형태로 reshape. MNIST 데이터는 grayscale 이미지기 때문에 3번째차원(컬러채널)의 값은 1.
x_image = tf.reshape(x, [-1, 28, 28, 1])
# 28x28x1 -> 28x28x32
h_conv1 = self.conv_layer_1(x_image)
# 28x28x32 -> 14x14x32
h_pool1 = self.pool_layer_1(h_conv1)
# 14x14x32 -> 14x14x64
h_conv2 = self.conv_layer_2(h_pool1)
# 14x14x64 -> 7x7x64
h_pool2 = self.pool_layer_2(h_conv2)
# 7x7x64(3136) -> 1024
h_pool2_flat = self.flatten_layer(h_pool2)
h_fc1 = self.fc_layer_1(h_pool2_flat)
# 1024 -> 10
logits = self.output_layer(h_fc1)
y_pred = tf.nn.softmax(logits)
return y_pred, logits
대략 이런 구조
# cross-entropy 손실 함수를 정의
@tf.function
def cross_entropy_loss(logits, y):
return tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=y))
# 최적화를 위한 Adam 옵티마이저를 정의
optimizer = tf.optimizers.Adam(1e-4) #0.0001
# 최적화를 위한 function을 정의
@tf.function
def train_step(model, x, y): #실제 Gradient Descent 한번 수행
with tf.GradientTape() as tape:
y_pred, logits = model(x)
loss = cross_entropy_loss(logits, y)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
# 모델의 정확도를 출력하는 함수를 정의
@tf.function
def compute_accuracy(y_pred, y):
correct_prediction = tf.equal(tf.argmax(y_pred,1), tf.argmax(y,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
return accuracy
# Convolutional Neural Networks(CNN) 모델을 선언
CNN_model = CNN()
# 10000 Step만큼 최적화를 수행
for i in range(10000):
# 50개씩 MNIST 데이터를 불러옴
batch_x, batch_y = next(train_data_iter)
# 100 Step마다 training 데이터셋에 대한 정확도를 출력
if i % 100 == 0:
train_accuracy = compute_accuracy(CNN_model(batch_x)[0], batch_y)
print("반복(Epoch): %d, 트레이닝 데이터 정확도: %f" % (i, train_accuracy))
# 옵티마이저를 실행해 파라미터를 한스텝 업데이트
train_step(CNN_model, batch_x, batch_y)
# 학습이 끝나면 학습된 모델의 정확도를 출력
print("정확도(Accuracy): %f" % compute_accuracy(CNN_model(x_test)[0], y_test))
결과
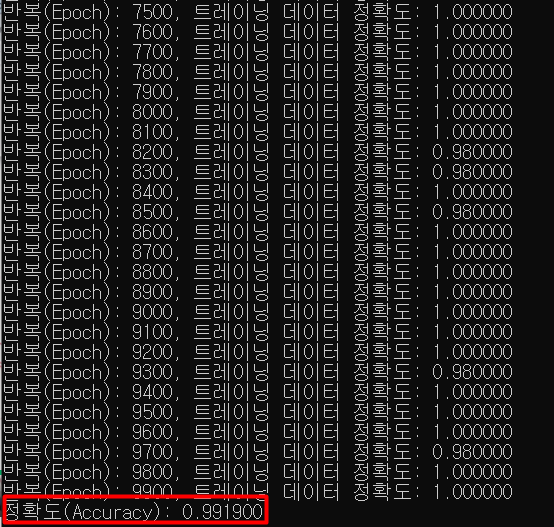
10000번의 epoch 결과, 정확도는 99% 정도가 나왔다. 앞서 실습했던 모델들과 비교하면 CNN 구조의 정확도가 월등히 높은 것을 확인할 수 있다.
# -*- coding: utf-8 -*-
# 텐서플로우를 이용한 ANN(Artificial Neural Networks) 구현 - Keras API를 이용한 구현
import tensorflow as tf
# MNIST 데이터를 다운로드
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
# 이미지들을 float32 데이터 타입으로 변경
x_train, x_test = x_train.astype('float32'), x_test.astype('float32')
# 28*28 형태의 이미지를 784차원으로 flattening 함
x_train, x_test = x_train.reshape([-1, 784]), x_test.reshape([-1, 784])
# [0, 255] 사이의 값을 [0, 1]사이의 값으로 Normalize 함
x_train, x_test = x_train / 255., x_test / 255.
# 레이블 데이터에 one-hot encoding을 적용
y_train, y_test = tf.one_hot(y_train, depth=10), tf.one_hot(y_test, depth=10)
# 학습을 위한 설정값들을 정의
learning_rate = 0.001
num_epochs = 30 # 학습횟수
batch_size = 256 # 배치개수
display_step = 1 # 손실함수 출력 주기
input_size = 784 # 28 * 28
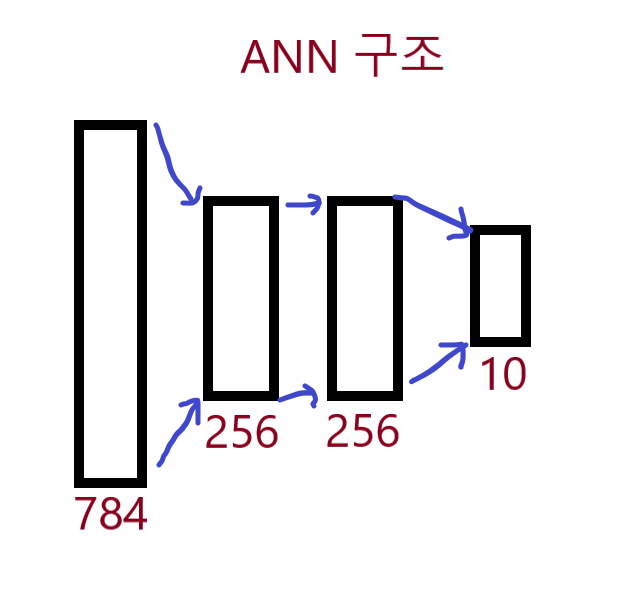
hidden1_size = 256
hidden2_size = 256
output_size = 10
# tf.data API를 이용해서 데이터를 섞고 batch 형태로 가져옴
train_data = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_data = train_data.shuffle(60000).batch(batch_size) # 한번 epoch가 끝날 때마다 셔플(섞어줌)
# 초기 W값과 b 값을 초기화
def random_normal_intializer_with_stddev_1():
return tf.keras.initializers.RandomNormal(mean=0.0, stddev=1.0, seed=None)
대충 그리자면 이런 구조다
# tf.keras.Model을 이용해서 ANN 모델을 정의
class ANN(tf.keras.Model):
def __init__(self):
super(ANN, self).__init__()
self.hidden_layer_1 = tf.keras.layers.Dense(hidden1_size,
activation='relu',
kernel_initializer=random_normal_intializer_with_stddev_1(),
bias_initializer=random_normal_intializer_with_stddev_1())
self.hidden_layer_2 = tf.keras.layers.Dense(hidden2_size,
activation='relu',
kernel_initializer=random_normal_intializer_with_stddev_1(),
bias_initializer=random_normal_intializer_with_stddev_1())
self.output_layer = tf.keras.layers.Dense(output_size,
activation=None,
kernel_initializer=random_normal_intializer_with_stddev_1(),
bias_initializer=random_normal_intializer_with_stddev_1())
def call(self, x):
H1_output = self.hidden_layer_1(x)
H2_output = self.hidden_layer_2(H1_output)
logits = self.output_layer(H2_output)
return logits
# cross-entropy 손실 함수를 정의
@tf.function
def cross_entropy_loss(logits, y):
return tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=y))
# 최적화를 위한 Adam 옵티마이저를 정의, 기본 옵티마이저를 업그레이드 한 것. 미분값이 0인 곳도 넘어감
optimizer = tf.optimizers.Adam(learning_rate)
# 최적화를 위한 function을 정의
@tf.function
def train_step(model, x, y): #한 번의 Gradient Descent 수행
with tf.GradientTape() as tape:
y_pred = model(x)
loss = cross_entropy_loss(y_pred, y)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
# 모델의 정확도를 출력하는 함수를 정의
@tf.function
def compute_accuracy(y_pred, y):
correct_prediction = tf.equal(tf.argmax(y_pred,1), tf.argmax(y,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
return accuracy
# ANN 모델을 선언
ANN_model = ANN()
# 지정된 횟수만큼 최적화를 수행
for epoch in range(num_epochs):
average_loss = 0.
total_batch = int(x_train.shape[0] / batch_size)
# 모든 배치들에 대해서 최적화를 수행
for batch_x, batch_y in train_data:
# 옵티마이저를 실행해서 파라마터들을 업데이트
_, current_loss = train_step(ANN_model, batch_x, batch_y), cross_entropy_loss(ANN_model(batch_x), batch_y)
# 평균 손실을 측정
average_loss += current_loss / total_batch
# 지정된 epoch마다 학습결과를 출력
if epoch % display_step == 0:
print("반복(Epoch): %d, 손실 함수(Loss): %f" % ((epoch+1), average_loss))
# 테스트 데이터를 이용해서 학습된 모델이 얼마나 정확한지 정확도를 출력
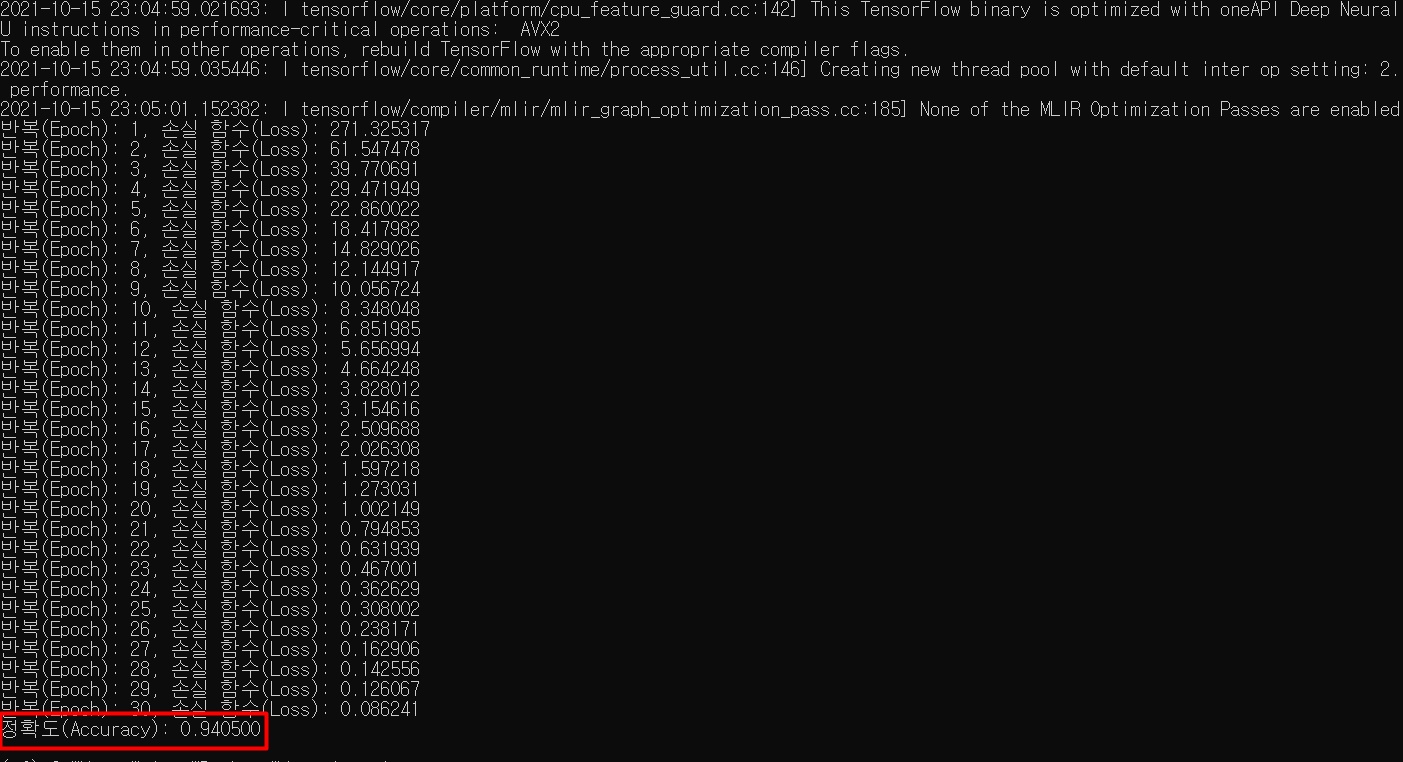
print("정확도(Accuracy): %f" % compute_accuracy(ANN_model(x_test), y_test)) # 정확도: 약 94%
결과
epoch 횟수 별로 손실함수 값이 어떻게 변화하는지 알 수 있다.
(한 번의 epoch는 인공 신경망에서 전체 데이터 셋에 대해 forward pass/backward pass 과정을 거친 것을 말함. 즉, 전체 데이터 셋에 대해 한 번 학습을 완료한 상태)